
고정 헤더 영역
상세 컨텐츠
본문
저번에 MySQL 설치하고 아주 기초적인 문법에 대해서 배웠습니다. 이번 시간에는 테이블의 필드 추가, 수정, 삭제 및 select코드를 이용하여 테이블을 다루어 보겠습니다.

저번 시간에 member 테이블의 틀을 만들어봤습니다. member테이블을 다시 불러와서 확인해보고 필드를 추가해보겠습니다.
1. 필드 작업

테이블에 새로운 필드를 추가할 경우
'alter table 테이블명 add 필드명 데이터타입;'
의 방식을 따릅니다. 필드 추가한 후 제약조건을 not null으로 설정할 수 없습니다. 그 이유는 필드를 추가하면 value 내용이 없기 때문에 not null이 필연적이기 때문입니다.
순서대로 필드 수정하기와 삭제하기 문법입니다.
alter table 테이블명 modify column 필드명 데이터타입;
alter table 테이블명 drop 필드명;

modify 쿼리를 통해 varchar(10)에서 varchar(20)으로 수정합니다.
drop 쿼리를 이용하여 mbti 필드를 삭제합니다.
테이블을 생성하여 필드까지 추가, 생성, 삭제 등 작업하는 방법을 익혔습니다. 각 필드마다 데이터를 입력하는 방법에 대해서 알아보겠습니다.
2. 데이터 다루기

위의 문법을 이용하여 words 테이블을 생성하여 필드와 데이터까지 입력해보겠습니다.

desc 명령어를 통해 특정 테이블에 어떤 column이 있는지 구조는 어떻게 되는지 조회할 수 있습니다.



1번과 2번 모두 데이터를 삽입할 수 있는 방법입니다. 1번은 기본값이 있더라도 컬럼 개수가 데이터 개수와 일치하지 않으면 에러가 발생합니다. 반면, 2번은 기본값을 처리할 수 있어 기본값이 있는 필드인 경우 해당 데이터는 생략 가능합니다.
지난 시간에 배웠던 member 테이블에 필드마다 데이터를 삽입해줍니다.
제약 조건을 주의하며 데이터를 입력하여 실행합니다.

데이터 수정하는 문법에 대해서 알아보겠습니다.

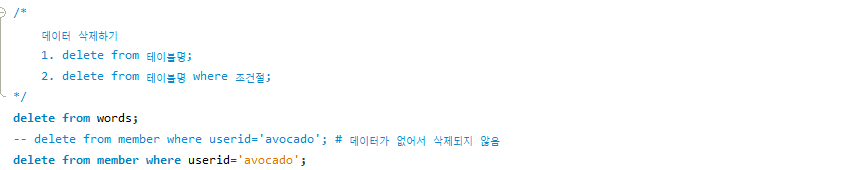
update worrds set eng = 'Lucy'; 쿼리문은 에러를 발생합니다. 세이프 모드로 인해서 에러가 발생하였기 때문에 세이프 모드를 해제하는 방법을 알아보겠습니다.


위의 창의 Safe Updates에 체크 표시되어 있다면 커서를 클릭하여 해제합니다.
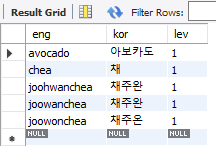
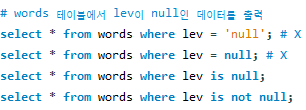
위에서 words의 데이터를 입력해주었습니다. words테이블내의 lev column 데이터를 1로 설정할 수 있습니다.

위에서 member 테이블에 데이터를 입력했습니다. point를 기본값으로 두었기 때문에 member 테이블의 point 데이터를 수정합니다. 스키마의 member 우클릭을 통해 select rows를 클릭합니다. member 테이블을 불러와 point 데이터를 수기로 수정하여 apply 를 통해 저장합니다.
| userid | point |
| apple | 150 |
| banana | 200 |
| melon | 300 |
| orange | 50 |
| avocado | 150 |

잠시 member클래스는 두고 words 클래스로 돌아오겠습니다.
eng 'avocado'의 lev 데이터 수정과 eng 'Brian'의 kor '브래이언', lev 2로 데이터를 수정할 수 있습니다.


다시 member 클래스로 돌아와 words 클래스와 같이 데이터를 수정해보겠습니다.


더보기
밑에서부터 삭제되었던 userid = 'avocado'가 포함되어서 결과가 나타나니 양해 부탁드립니다...
또 밑에서 추가될 userid = cherry가 계속해서 결과에 포함되니 양해 부탁드립니다...
select 쿼리를 이용하여 데이터를 검색할 수 있습니다.

words 테이블의 데이터를 다 삭제하였기 때문에 다시 insert 명령문을 이용하여 데이터를 입력해줍니다.

select 쿼리를 순서대로 실행하여 출력한 결과입니다.









as를 이용하여 필드에 별명을 붙일 수 있습니다.

select eng, kor, lev from words; # 위와 같은 값을 출력(결과 사진 생략)




SQL에도 연산자가 존재합니다.
산술연산자
비교 연산자
대입 연산자
논리 연산자
기타 연산자
순서대로 확인해보겠습니다!
3. SQL 연산자


>=으로 '이상'을 표현합니다.

member 테이블로부터 userid = 'apple' 과 userpw = '1111' 모두 만족하는 userid를 출력하라고 했으니 'apple' 데이터가 적절하게 출력됩니다.
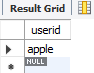
위와 달리 userpw = '1234'로 '1111'이 아니기 때문에 null 값이 출력됩니다.

null인 데이터를 출력하기 위해서는 대입 연산자 '=' 이 아니라 기타 연산자 중 'is'를 이용합니다.
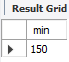
0 이상 150이하 연산을 흔히 <=, >= 을 이용한 방법만 알고 있는 경우가 많습니다.
sql에서는 between을 이용하여 나타낼 수도 있습니다.



like 연산자를 이용하여 x로 시작하는 문자열, x로 끝나는 문자열, x를 포함하는 문자열 모두 출력할 수 있습니다.

출력내용을 순서대로 확인해주세요.



4. 정렬하기
order by 쿼리문을 이용하여 오름차순, 내림차순을 나타낼 수 있습니다.




여기서 삭제했던 userid='avocado'와 userid = 'cherry'를 새롭게 입력해줍니다.



order by를 이용하여 point 필드를 오름차순으로 정렬할 수 있습니다.

name = '안가도'와 '채리'의 포인트가 같습니다. 같은 포인트끼리 비교할 수도 있습니다.
성별을 서로 같게 만들어 같은 포인트끼리 비교하기 용이하게 만들 수 있습니다.

수기로 수정하여 apply를 클릭하여 바꿀 수 있습니다.



avocado와 cherry의 알파벳중 avocado의 'a'가 'c'보다 우선되기 때문에 a -> c 순으로 정렬됩니다.
limit을 이용하여 일부 갯수의 로우만 출력할 수도 있습니다.





6. 집계(그룹) 함수

두 번째 행부터 실행하면 출력 값은 다음과 같습니다.


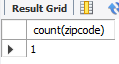







마지막 쿼리를 해석하면 다음과 같습니다.
member 테이블에서 gender 필드에 따라 '남자'와 '여자'로 구분한 후 gender 중에 '여자' 에 해당되는 gender의 데이터와 g와 count(userid)의 별명인 인원의 데이터를 함께 출력하라.



7. 데이터 정규화
- 데이터 베이스를 설계할 때 중복을 최소화하는 것
- 조직화되어 있지 않은 테이블과 관계들을 조직화된 테이블과 관계들로 나누는 것
데이터 정규화가 필요한 경우
- 데이터를 변경, 삽입, 삭제할 때 원하지 않게 데이터가 삭제되거나 가공되는 일이 발생할 수 있음(이상 현상)
- 이상 현상이 발생할 가능성이 있다면 정규화가 필요
정규화의 종류
| 1NF(제 1정규화) | - 테이블 안의 모든 값들은 단일 값이어야 함 - 더 이상 쪼갤 수 없는 단위로 저장 |
| 2NF(제 2정규화) | - 1NF를 만족하면서 완전 함수 종속성을 가진 관계들로만 테이블을 생성 - 종속성들 중 종속 관계에 있는 열들끼리 테이블을 구분해 주는 것 - 기본 키에 속하지 않은 속성 모두가 기본 키에 완전 함수 종속인 정규형 * 함수 종속성: x값에 따라 y값이 결정되는 경우 |
| 3NF(제 3정규화) | - 2NF를 만족하면서, 기본 키에 대해 이행적 함수 종속이 되지 않는 것을 의미 |
| 비정규화 | - 정규형에 일치하게 되어 있는 테이블을 정규형을 지키지 않는 테이블로 변경 - 테이블을 조회하는 용도로 사용하거나, 너무 데이터가 많이 나뉘어 성능이 저하된다면 비정규화를 하여 테이블을 다루는 것이 더 효율적일 수 있음 - 어떤 작업을 수행하는지, 어떤 데이터를 사용하는지에 따라 적절한 자유화를 하는 것이 좋음 |
이제 정규화의 사용에 대해서 알아보겠습니다.
(i) 제 1정규화

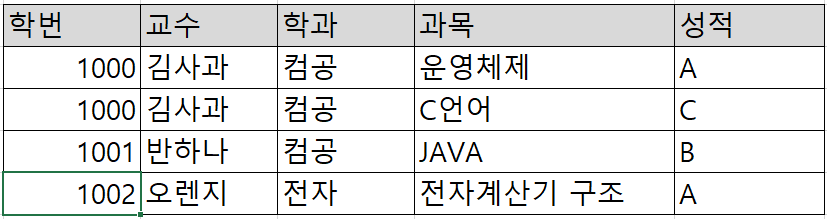
위의 사진을 살펴보면 첫번째 행과 세번째 행의 과목과 성적의 데이터가 단일 값이 아니기 때문에 단일 값으로 변경해야 합니다. 행을 추가하면 단일 값으로 만들 수 있습니다.
(ii) 제 2정규화
partial dependency를 제거한 테이블
제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것. 기본키 중에 특정 컬럼에만 종 속된 컬럼이 없어야 함.

학생이 시험 본 과목에 따라 성적이 바뀐다는 것을 알고 있습니다.
또, 해당 학과의 교수의 가르치는 과목이 종속적인 것도 알고 있습니다.
따라서 성적 테이블, 과목 테이블 두 개의 테이블로 나눌 수 있습니다.
학번, 성적을 합하여 과목코드 primary key를 생성합니다.
학번, 과목 코드 ===> 성적
과목 코드, 교수, 학과 ===> 과목


(iii) 제 3정규화
제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것. 기본키 이외에 다른 컬럼이 그 외의 다른 컬럼을 결정 할 수 없다는 것을 의미




7. 조인(Join)
테이블 하나에 원하는 데이커가 존재하는 경우도 있지만 두 개의 테이블을 합쳐야 하는 경우도 존재합니다. 이런 경우 조인 쿼리를 사용하여 두 개의 테이블을 합쳐서 원하는 데이터를 추출할 수 있습니다.
예시를 통해 조인 문법을 이해하기 위해 profile 테이블을 생성합니다.


insert 쿼리를 이용하여 데이터를 입력합니다.
foreign key를 userid로 설정하여 member테이블의 userid 필드를 참조하도록 합니다.


* grape는 member테이블의 userid필드 내에 포함된 데이터가 없기 때문에 에러가 발생합니다.
join 문법은 다음과 같습니다.

7-1. inner 조인

- 조인하는 테이블의 on 절의 조건이 일치하는 결과만 출력 (두 테이블의 교집합)
- join, inner join, cross join 모두 같은 의미로 사용됨


userid 'apple', 'avocado', 'orange'가 두 테이블의 교집합의 요인입니다.

7-1. left/right 조인
- 두 테이블이 조인할 때 왼쪽 또는 오른쪽을 기준으로 기준 테이블의 데이터를 모두 출력



교집합에 속하는 요인과 m.userid에 속한 요인들이 합쳐진 데이터들이 출력됩니다.

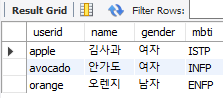
교집합에 속하는 요인과 p.userid에 속한 요인들이 합쳐진 데이터들이 출력됩니다. 결국에는 그 값이 교집합에 속하는 요인들 뿐입니다.
'MySQL' 카테고리의 다른 글
| MySQL 03. 문법(2)(서브 쿼리, View..등) (0) | 2024.03.29 |
|---|---|
| Python과 MySQL 연동하기 (0) | 2024.03.28 |
| Python 25. MySQL 첫걸음... (0) | 2024.03.25 |




